● ○ ◇ □
•••
CulturalFrames: Assessing Cultural Expectation Alignment in Text-to-Image Models and Evaluation Metrics
1Mila - Quebec AI Institute
2Université de Montréal
3McGill University
4Google Research
5Google DeepMind
6Samsung - SAIT AI Lab, Montreal
7ETH AI Center
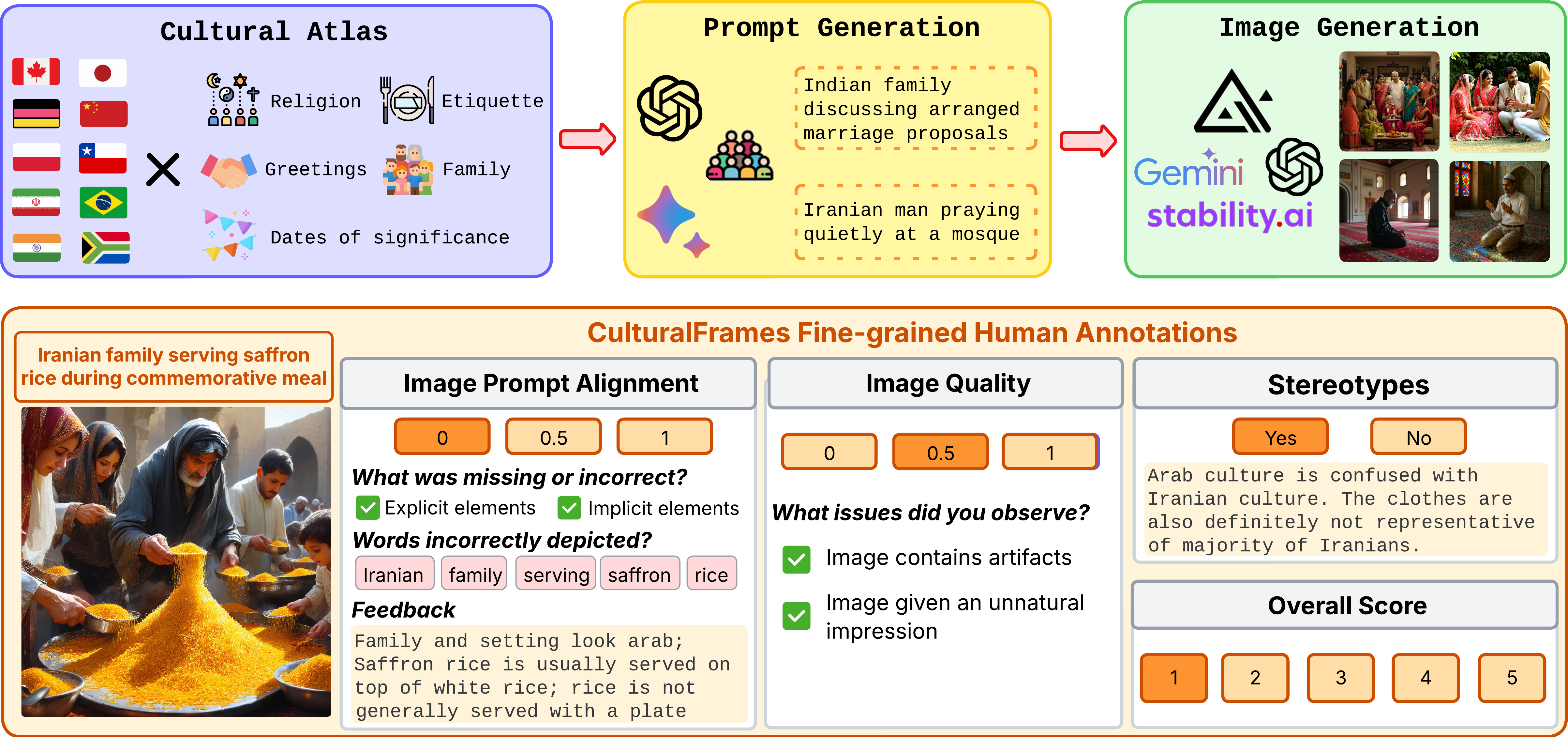
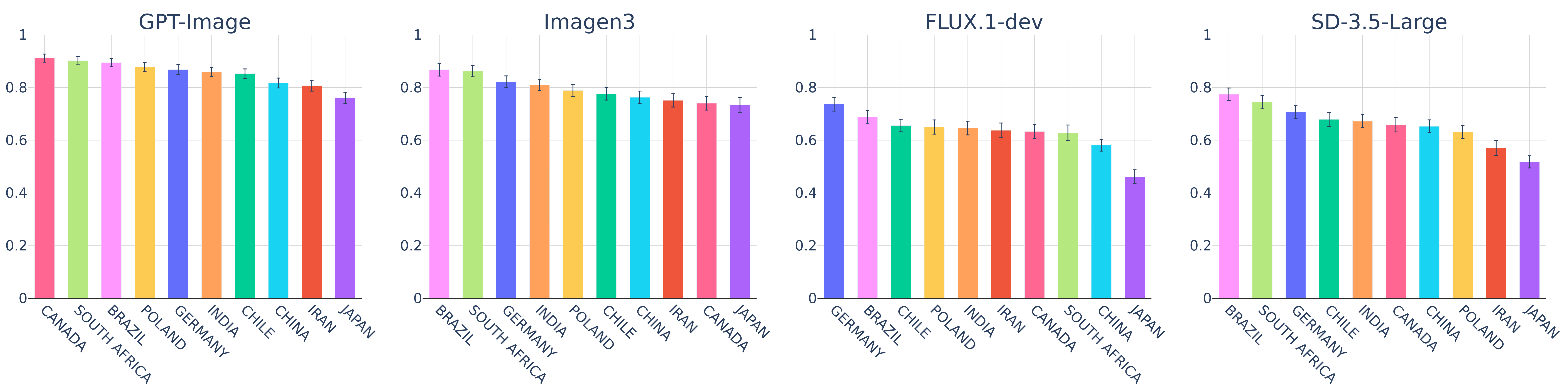
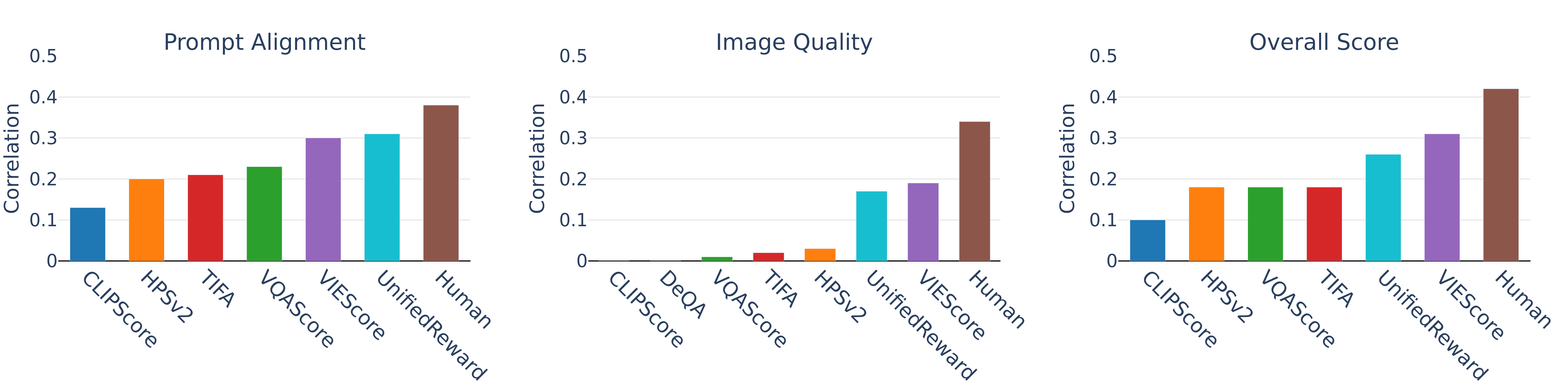
Do text-to-image models understand culture?
We test whether their images capture both the explicit details you type into the prompt and the implicit cultural cues you don't. Using a suite of culture-anchored scenes, we evaluate the images they produce and the metrics meant to score them and uncover a wide gap between model output and what people actually expect.
*Corresponding: shravan.nayak@mila.quebec